Cadre NVIDIA NeMo

Caractéristiques
- Nom du produit: Cadre NVIDIA NeMo
- Plates-formes concernées : Windows, Linux, macOS
- Versions concernées : Toutes les versions antérieures à 24
- Vulnérabilité de sécurité : CVE-2025-23360
- Score de base de l'évaluation des risques : 7.1 (CVSS v3.1)
Instructions d'utilisation du produit
Installation de la mise à jour de sécurité :
Pour protéger votre système, suivez ces étapes :
- Téléchargez la dernière version depuis la page des versions de NeMo-Framework-Launcher sur GitHub.
- Accédez à la section Sécurité des produits NVIDIA pour plus d’informations.
Détails de la mise à jour de sécurité :
La mise à jour de sécurité corrige une vulnérabilité dans NVIDIA NeMo Framework qui pourrait entraîner l'exécution de code et la perte de données.amper.
Mise à jour logicielle:
Si vous utilisez une version de branche antérieure, il est recommandé de procéder à une mise à niveau vers la dernière version de branche pour résoudre le problème de sécurité.
Surview
NVIDIA NeMo Framework est un framework d'IA générative évolutif et natif du cloud conçu pour les chercheurs et les développeurs travaillant sur Modèles de langage volumineux, Multimodal et IA vocale (par exemple Reconnaissance automatique de la parole et Synthèse vocale). Il permet aux utilisateurs de créer, personnaliser et déployer efficacement de nouveaux modèles d'IA génératifs en exploitant le code existant et les points de contrôle des modèles pré-entraînés.
Instructions d'installation: Installer NeMo Framework
NeMo Framework offre un support complet pour le développement de modèles de langage volumineux (LLM) et de modèles multimodaux (MM). Il offre la flexibilité d'une utilisation sur site, dans un centre de données ou avec votre fournisseur cloud préféré. Il prend également en charge l'exécution dans des environnements compatibles SLURM ou Kubernetes.

Conservation des données
Conservateur NeMo [1] est une bibliothèque Python qui inclut une suite de modules pour l'exploration de données et la génération de données synthétiques. Évolutifs et optimisés pour les GPU, ils sont parfaits pour la conservation de données en langage naturel afin d'entraîner ou d'affiner les LLM. Avec NeMo Curator, vous pouvez extraire efficacement du texte de haute qualité à partir de données brutes volumineuses. web sources de données.
Formation et personnalisation
NeMo Framework fournit des outils pour une formation et une personnalisation efficaces Masters de LLM et modèles multimodaux. Il inclut des configurations par défaut pour la configuration des clusters de calcul, le téléchargement des données et les hyperparamètres des modèles, qui peuvent être ajustés pour l'entraînement sur de nouveaux jeux de données et modèles. Outre le pré-entraînement, NeMo prend en charge les techniques de réglage fin supervisé (SFT) et de réglage fin optimisé des paramètres (PEFT), telles que LoRA, Ptuning, etc.
Deux options sont disponibles pour lancer la formation dans NeMo : en utilisant l'interface API NeMo 2.0 ou avec NeMo Run.
- Avec NeMo Run (recommandé) : NeMo Run fournit une interface permettant de simplifier la configuration, l'exécution et la gestion des expériences dans différents environnements de calcul. Cela inclut le lancement de tâches sur votre poste de travail en local ou sur de grands clusters, compatibles SLURM ou Kubernetes dans un environnement cloud.
- Pré-formation et démarrage rapide PEFT avec NeMo Run
- Utilisation de l'API NeMo 2.0 : Cette méthode fonctionne parfaitement avec une configuration simple impliquant de petits modèles, ou si vous souhaitez créer votre propre chargeur de données personnalisé, des boucles d'entraînement ou modifier les couches du modèle. Elle vous offre plus de flexibilité et de contrôle sur les configurations, et facilite leur extension et leur personnalisation par programmation.
-
TraDémarrage rapide avec l'API NeMo 2.0
-
Migration de l'API NeMo 1.0 vers NeMo 2.0
-
Alignement
- Aligneur NeMo [1] est une boîte à outils évolutive pour un alignement efficace des modèles. Elle prend en charge des algorithmes d'alignement de modèles de pointe tels que SteerLM, DPO, l'apprentissage par renforcement à partir du feedback humain (RLHF), et bien d'autres. Ces algorithmes permettent aux utilisateurs d'aligner les modèles linguistiques pour les rendre plus sûrs, plus sûrs et plus utiles.
- Tous les points de contrôle NeMo-Aligner sont compatibles avec l'écosystème NeMo, permettant une personnalisation et un déploiement d'inférence supplémentaires.
Flux de travail étape par étape des trois phases du RLHF sur un petit modèle GPT-2B :
- Formation SFT
- Formation au modèle de récompense
- Formation PPO
De plus, nous démontrons un support pour diverses autres nouvelles méthodes d’alignement :
- Délégué à la protection des données: un algorithme d'alignement léger comparé à RLHF avec une fonction de perte plus simple.
- Jeu autonome Réglage fin (SPIN)
- SteerLM : une technique basée sur le SFT conditionné, avec une sortie orientable.
Consultez la documentation pour plus d'informations : Documentation d'alignement
Modèles multimodaux
- NeMo Framework fournit un logiciel optimisé pour former et déployer des modèles multimodaux de pointe dans plusieurs catégories : modèles de langage multimodaux, fondements vision-langage, modèles texte-image et au-delà de la génération 2D à l'aide de champs de rayonnement neuronal (NeRF).
- Chaque catégorie est conçue pour répondre aux besoins spécifiques et aux avancées du domaine, en s'appuyant sur des modèles de pointe pour gérer une large gamme de types de données, notamment du texte, des images et des modèles 3D.
Note
Nous migrons la prise en charge des modèles multimodaux de NeMo 1.0 vers NeMo 2.0. Si vous souhaitez explorer ce domaine en attendant, veuillez consulter la documentation de la version NeMo 24.07 (précédente).
Déploiement et inférence
NeMo Framework fournit différents chemins pour l'inférence LLM, répondant à différents scénarios de déploiement et besoins de performances.
Déployer avec NVIDIA NIM
- NeMo Framework s'intègre parfaitement aux outils de déploiement de modèles d'entreprise grâce à NVIDIA NIM. Cette intégration est optimisée par NVIDIA TensorRT-LLM, garantissant une inférence optimisée et évolutive.
- Pour plus d'informations sur NIM, visitez le site NVIDIA website.
Déployer avec TensorRT-LLM ou vLLM
- NeMo Framework propose des scripts et des API pour exporter des modèles vers deux bibliothèques optimisées pour l'inférence, TensorRT-LLM et vLLM, et pour déployer le modèle exporté avec le serveur d'inférence NVIDIA Triton.
- Pour les scénarios nécessitant des performances optimisées, les modèles NeMo peuvent exploiter TensorRT-LLM, une bibliothèque spécialisée pour accélérer et optimiser l'inférence LLM sur les GPU NVIDIA. Ce processus implique la conversion des modèles NeMo dans un format compatible avec TensorRT-LLM à l'aide du module nemo.export.
- Déploiement du LLM terminéview
- Déployer les modèles de langage NeMo Large avec NIM
- Déployer les grands modèles de langage NeMo avec TensorRT-LLM
- Déployer les grands modèles de langage NeMo avec vLLM
Modèles pris en charge
Modèles de langage volumineux
| Modèles de langage volumineux | Pré-formation et SFT | PEFT | Alignement | Convergence de la formation FP8 | TRT/TRTLLM | Conversion vers et depuis le visage enlacé | Évaluation |
|---|---|---|---|---|---|---|---|
| Llama3 8B/70B, Llama3.1 405B | Oui | Oui | x | Oui (partiellement vérifié) | Oui | Les deux | Oui |
| Mixtral 8x7B/8x22B | Oui | Oui | x | Oui (non vérifié) | Oui | Les deux | Oui |
| Nemotron 3 8B | Oui | x | x | Oui (non vérifié) | x | Les deux | Oui |
| Nemotron 4 340B | Oui | x | x | Oui (non vérifié) | x | Les deux | Oui |
| Baichuan2 7B | Oui | Oui | x | Oui (non vérifié) | x | Les deux | Oui |
| ChatGLM3 6B | Oui | Oui | x | Oui (non vérifié) | x | Les deux | Oui |
| Gemma 2B/7B | Oui | Oui | x | Oui (non vérifié) | Oui | Les deux | Oui |
| Gemma2 2B/9B/27B | Oui | Oui | x | Oui (non vérifié) | x | Les deux | Oui |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | Oui | Oui | x | Oui (non vérifié) | x | x | Oui |
| Phi3 mini 4k | x | Oui | x | Oui (non vérifié) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | Oui | Oui | x | Oui (non vérifié) | Oui | Les deux | Oui |
| StarCoder 15B | Oui | Oui | x | Oui (non vérifié) | Oui | Les deux | Oui |
| StarCoder2 3B/7B/15B | Oui | Oui | x | Oui (non vérifié) | Oui | Les deux | Oui |
| BERT 110M/340M | Oui | Oui | x | Oui (non vérifié) | x | Les deux | x |
| T5 220M/3B/11B | Oui | Oui | x | x | x | x | x |
Modèles de langage visuel
| Modèles de langage visuel | Pré-formation et SFT | PEFT | Alignement | Convergence de la formation FP8 | TRT/TRTLLM | Conversion vers et depuis le visage enlacé | Évaluation |
|---|---|---|---|---|---|---|---|
| NeVA (LLaVA 1.5) | Oui | Oui | x | Oui (non vérifié) | x | Depuis | x |
| Llama 3.2 Vision 11B/90B | Oui | Oui | x | Oui (non vérifié) | x | Depuis | x |
| LLaVA Next (LLaVA 1.6) | Oui | Oui | x | Oui (non vérifié) | x | Depuis | x |
Modèles d'intégration
| Intégration de modèles de langage | Pré-formation et SFT | PEFT | Alignement | Convergence de la formation FP8 | TRT/TRTLLM | Conversion vers et depuis le visage enlacé | Évaluation |
|---|---|---|---|---|---|---|---|
| SBERT 340M | Oui | x | x | Oui (non vérifié) | x | Les deux | x |
| Lama 3.2 Incorporation 1B | Oui | x | x | Oui (non vérifié) | x | Les deux | x |
Modèles de la Fondation mondiale
| Modèles de la Fondation mondiale | Post-formation | Inférence accélérée |
|---|---|---|
| Cosmos-1.0-Diffusion-Text2World-7B | Oui | Oui |
| Cosmos-1.0-Diffusion-Text2World-14B | Oui | Oui |
| Cosmos-1.0-Diffusion-Video2World-7B | À venir | À venir |
| Cosmos-1.0-Diffusion-Video2World-14B | À venir | À venir |
| Cosmos-1.0-Autorégressif-4B | Oui | Oui |
| Cosmos-1.0-Autorégressif-Video2World-5B | À venir | À venir |
| Cosmos-1.0-Autorégressif-12B | Oui | Oui |
| Cosmos-1.0-Autorégressif-Video2World-13B | À venir | À venir |
Note
NeMo prend également en charge la préformation pour les architectures de diffusion et autorégressives text2world modèles de fondation.
IA vocale
Le développement de modèles d'IA conversationnelle est un processus complexe qui implique la définition, la construction et l'entraînement de modèles dans des domaines spécifiques. Ce processus nécessite généralement plusieurs itérations pour atteindre un niveau de précision élevé. Il implique souvent de multiples itérations pour atteindre une précision élevée, des ajustements précis sur diverses tâches et données spécifiques au domaine, la garantie des performances d'entraînement et la préparation des modèles pour le déploiement des inférences.
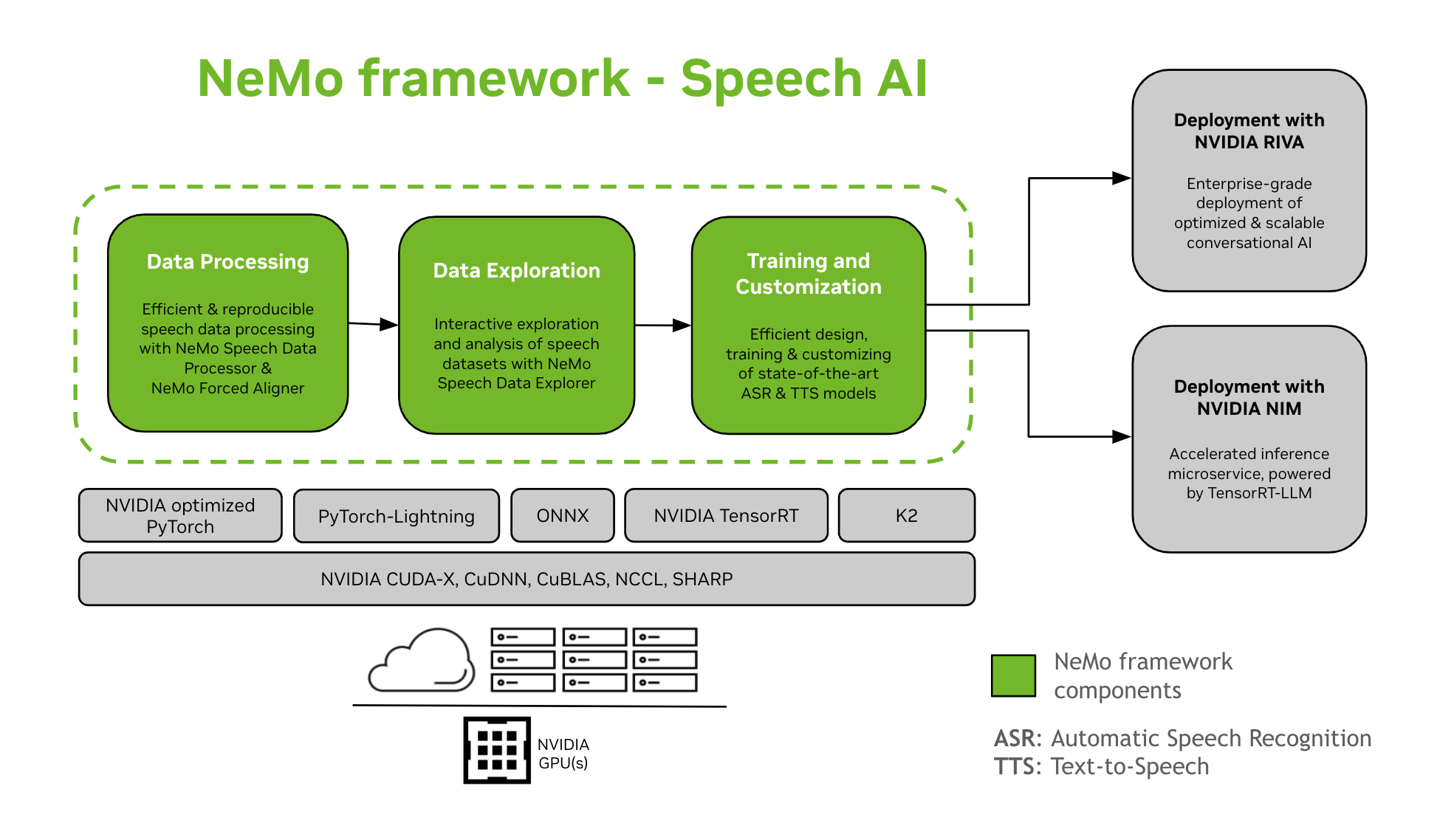
NeMo Framework prend en charge l'entraînement et la personnalisation des modèles d'IA vocale. Cela inclut des tâches telles que la reconnaissance automatique de la parole (RAP) et la synthèse vocale (TTS). Il assure une transition fluide vers un déploiement en production en entreprise avec NVIDIA Riva. Pour accompagner les développeurs et les chercheurs, NeMo Framework inclut des points de contrôle pré-entraînés de pointe, des outils de traitement reproductible des données vocales, ainsi que des fonctionnalités d'exploration et d'analyse interactives des ensembles de données vocales. Les composants de NeMo Framework pour l'IA vocale sont les suivants :
Formation et personnalisation
NeMo Framework contient tout ce qui est nécessaire pour former et personnaliser les modèles de parole (ASR, Classification de la parole, Reconnaissance des locuteurs, Journalisation des intervenants, et TTS) de manière reproductible.
Modèles pré-entraînés SOTA
- NeMo Framework fournit des recettes de pointe et des points de contrôle pré-entraînés de plusieurs ASR et TTS modèles, ainsi que des instructions sur la façon de les charger.
- Outils de parole
- NeMo Framework fournit un ensemble d'outils utiles pour développer des modèles ASR et TTS, notamment :
- Aligneur forcé NeMo (NFA) pour générer des temps au niveau du jeton, du mot et du segmentamps de parole dans l'audio en utilisant les modèles de reconnaissance vocale automatique basés sur CTC de NeMo.
- Processeur de données vocales (SDP), une boîte à outils pour simplifier le traitement des données vocales. Elle permet de représenter les opérations de traitement de données dans une configuration. file, minimisant le code standard et permettant la reproductibilité et le partage.
- Explorateur de données vocales (SDE), un système basé sur Dash web application pour l'exploration et l'analyse interactives d'ensembles de données vocales.
- Outil de création de jeux de données qui fournit une fonctionnalité pour aligner les longs fichiers audio files avec les transcriptions correspondantes et les diviser en fragments plus courts qui conviennent à la formation du modèle de reconnaissance automatique de la parole (ASR).
- Outil de comparaison pour les modèles ASR afin de comparer les prédictions de différents modèles ASR au niveau de la précision des mots et de l'énonciation.
- Évaluateur ASR pour évaluer les performances des modèles ASR et d'autres fonctionnalités telles que la détection d'activité vocale.
- Outil de normalisation de texte pour convertir un texte de la forme écrite à la forme parlée et vice versa (par exemple « 31 » contre « trente et unième »).
- Chemin vers le déploiement
- Les modèles NeMo formés ou personnalisés avec le framework NeMo peuvent être optimisés et déployés avec NVIDIA Riva. Riva fournit des conteneurs et des graphiques Helm spécialement conçus pour automatiser les étapes d'un déploiement en un clin d'œil.
Autres ressources
- NeMo: Le référentiel principal du framework NeMo
- NeMo–Courir:Un outil pour configurer, lancer et gérer vos expériences d'apprentissage automatique.
- Aligneur NeMo : Boîte à outils évolutive pour un alignement efficace des modèles
- NeMo-Curateur : Boîte à outils évolutive de prétraitement et de conservation des données pour les LLM
Engagez-vous avec la communauté NeMo, posez des questions, obtenez de l'aide ou signalez des bugs.
- Discussions sur NeMo
- Problèmes de NeMo
Langages et frameworks de programmation
- Python: L'interface principale pour utiliser NeMo Framework
- Torche électrique: NeMo Framework est construit sur PyTorch
Licences
- Le dépôt Github de NeMo est sous licence Apache 2.0
- NeMo Framework est sous licence NVIDIA AI PRODUCT ACCORD. En extrayant et en utilisant le conteneur, vous acceptez les termes et conditions de cette licence.
- Le conteneur NeMo Framework contient des matériaux Llama régis par l'accord de licence communautaire Meta Llama3.
Notes de bas de page
Actuellement, la prise en charge de NeMo Curator et NeMo Aligner pour les modèles multimodaux est en cours de développement et sera disponible très prochainement.
FAQ
Q : Comment puis-je vérifier si mon système est affecté par la vulnérabilité ?
R : Vous pouvez vérifier si votre système est affecté en vérifiant la version de NVIDIA NeMo Framework installée. Si elle est antérieure à la version 24, votre système est peut-être vulnérable.
Q : Qui a signalé le problème de sécurité CVE-2025-23360 ?
R : Le problème de sécurité a été signalé par Or Peles – JFrog Security. NVIDIA remercie son équipe pour sa contribution.
Q : Comment puis-je recevoir les futures notifications des bulletins de sécurité ?
R : Visitez la page Sécurité des produits NVIDIA pour vous abonner aux notifications des bulletins de sécurité et rester informé des mises à jour de sécurité des produits.
Documents / Ressources
 |
Cadre NVIDIA NeMo [pdf] Guide de l'utilisateur Cadre NeMo, NeMo, Cadre |